CompCert C is a compiler for the C programming language. Its intended use is the compilation of life-critical and mission-critical software written in C and meeting high levels of assurance. It accepts almost all of the ISO C 2011, ISO C 1999 and ANSI C languages, with some exceptions and a few extensions. It produces machine code for the PowerPC, ARM, x86 and RISC-V architectures. Performance of the generated code is decent but not outstanding: on ARM 64 bits, about 90% of the performance of GCC version 11 at optimization level 1.
What sets CompCert C apart from any other production compiler, is that it is formally verified, using machine-assisted mathematical proofs, to be exempt from miscompilation issues. In other words, the executable code it produces is proved to behave exactly as specified by the semantics of the source C program. This level of confidence in the correctness of the compilation process is unprecedented and contributes to meeting the highest levels of software assurance. In particular, using the CompCert C compiler is a natural complement to applying formal verification techniques (static analysis, program proof, model checking) at the source code level: the correctness proof of CompCert C guarantees that all safety properties verified on the source code automatically hold as well for the generated executable.
Compilers are complicated pieces of software that implement delicate algorithms. Bugs in compilers do occur and can cause incorrect executable code to be silently generated from a correct source program. In other words, a buggy compiler can insert bugs in the programs that it compiles. This phenomenon is called miscompilation.
Several empirical studies demonstrate that many popular production compilers suffer from miscompilation issues. For example, in 1995, the authors of the Nullstone C conformance test suite reported that
Nullstone isolated defects [in integer division] in twelve of twenty commercially available compilers that were evaluated. (https://www.nullstone.com/htmls/category/divide.htm)
A decade later, E. Eide and J. Regehr showed similar sloppiness in C compilers, this time concerning volatile memory accesses:
We tested thirteen production-quality C compilers and, for each, found situations in which the compiler generated incorrect code for accessing volatile variables. This result is disturbing because it implies that embedded software and operating systems — both typically coded in C, both being bases for many mission-critical and safety-critical applications, and both relying on the correct translation of volatiles — may be being miscompiled. [3]
More recently, Yang et al generalized their testing of C compilers and, again, found many instances of miscompilation:
We created a tool that generates random C programs, and then spent two and a half years using it to find compiler bugs. So far, we have reported more than 325 previously unknown bugs to compiler developers. Moreover, every compiler that we tested has been found to crash and also to silently generate wrong code when presented with valid inputs. [13]
For non-critical, “everyday” software, miscompilation is an annoyance but not a major issue: bugs introduced by the compiler are negligible compared to those already present in the source program. The situation changes dramatically, however, for safety-critical or mission-critical software, where human lives, critical infrastructures, or highly-sensitive information are at stake. There, miscompilation is a non-negligible risk that must be addressed by additional, difficult and costly verification activities such as extra testing and code reviews of the generated assembly code.
An especially worrisome aspect of the miscompilation problem is that it weakens the usefulness of formal, tool-assisted verification of source programs. Increasingly, the development process for critical software includes the use of formal verification tools such as static analyzers, deductive verifiers (program provers), and model checkers. Advanced verification tools are able to automatically establish valuable safety properties of the program, such as the absence of run-time errors (no out-of-bound array accesses, no arithmetic overflows, etc). However, most of these tools operate at the level of C source code. A buggy compiler has the potential to invalidate the safety guarantees provided by source-level formal verification, producing an incorrect executable that crashes or misbehaves from a formally-verified source program.
The CompCert project puts forward a radical, mathematically-grounded solution to the miscompilation problem: the formal, tool-assisted verification of the compiler itself. By applying program proof techniques to the source code of the compiler, we can prove, with mathematical certainty, that the executable code produced by the compiler behaves exactly as specified by the semantics of the source C program, therefore ruling out all risks of miscompilation [7].
Compiler verification, as outlined above, is not a new idea: the first compiler correctness proof (for the translation of arithmetic expressions to a stack machine) was published in 1967 [9], then mechanized as early as 1972 using the Stanford LCF proof assistant [10]. Since then, compiler verification has been the topic of much academic research. The CompCert project carries this line of work all the way to a complete, realistic, optimizing compiler than can be used in the production of critical embedded software systems.
Semantic preservation The formal verification of CompCert consists in proving the following theorem, which we take as the high-level specification of a correct compiler:
Semantic preservation theorem:
For all source programs S and compiler-generated code C,
if the compiler, applied to the source S, produces the code C,
without reporting a compile-time error,
then the observable behavior of C improves on one of the allowed observable behaviors of S.
In CompCert, this theorem has been proved, with the help of the Rocq/Coq proof assistant, taking S to be abstract syntax trees for the CompCert C language (after preprocessing, parsing, type-checking and elaboration), and C to be abstract syntax trees for the assembly-level Asm language (before assembling and linking). (See section 1.3 for more details.)
There are three noteworthy points in the statement of semantic preservation above:
What are observable behaviors? In a nutshell, they include everything the user of the program, or the physical world in which it executes, can “see” about the actions of the program, with the notable exception of execution time and memory consumption. More precisely, we follow the ISO C standards in considering that we can observe:
The observable behavior of a program is, therefore, a trace of all I/O and volatile operations it performs, plus an indication of whether it terminates and how it terminates (normally or on an error).
How do we define the possible behaviors of a source or executable program? This is the purpose of a formal semantics for the corresponding languages. A formal semantics is a mathematically-defined relation between programs and their possible behaviors. Several such semantics are defined as part of CompCert’s verification, including one for the CompCert C language and one for the Asm language (assembly code for each of the supported target platforms). These semantics can be viewed as mathematically-precise renditions of (relevant parts of) the ISO C 99 standard document and of (relevant parts of) the reference manuals for the PowerPC, ARM, RISC-V and x86 architectures.
What does semantic preservation tell us about source-level verification? A straightforward corollary of the semantic preservation theorem shows the following:
Let Σ be a set of acceptable behaviors, characterizing a desired safety or liveness property of the program.
Assume that a source program S satisfies Σ: all possible observable behaviors of S are in Σ.
Further assume that the compiler, applied to the source S, produces the code C.
Then, the compiled code C satisfies Σ: the observable behavior of C is in Σ.
The purpose of a sound source-level verification tool is precisely to establish that a specification Σ holds for all possible executions of a source program S. The specification can be defined by the user, for instance as pre- and post-conditions, or fixed by the tool, for instance the absence of run-time errors. Therefore, a formally-verified compiler guarantees that if a sound source-level verification tool says “yes, this program satisfies this specification”, then the compiled code that really executes also satisfies this specification. In other words, using a formally-verified compiler justifies verification at the source level, insofar as the guarantees established over the source program carry over to the compiled code that actually executes in the end.
How do we conduct the proof of semantic preservation? Because of the inherent complexity of an optimizing compiler, the proof is a major endeavor. We split it into 15 separate proofs of semantic preservation, one for each pass of the CompCert compiler. The final semantic preservation theorem, then, follows from the composition of these separate proofs. For every pass, we must prove semantic preservation for all possible input programs and for all possible executions of the input program (there can be many such executions depending on the unpredictable results of input operations). To this end, we need to consider every possible reachable state in the execution of the program and every transition that can be performed from this state according to the formal semantics. The proofs take advantage of the inductive structure of programming languages: for example, to show that a compound expression a + b is correctly compiled, we assume, by induction hypothesis, that the two smaller subexpressions a and b are correctly compiled, then combine these results with reasoning specific to the + operator.
If the compiler proof were conducted using paper and pencil, it would fill hundreds of pages, and no mathematician would be willing to check it. Instead, we leverage the power of the computer: CompCert’s proof of correctness is conducted using the Rocq prover, previously known as the Coq proof assistant, a software tool that helps us construct the proof interactively, then automatically re-checks the validity of the proof [2, 11]. Such mechanization of the proof brings near-absolute confidence in its validity.
How effective is formal compiler verification? As mentioned above and detailed in section 1.3, CompCert is still a work in progress, and complete, end-to-end formal verification has not been achieved yet: as of this writing, about 90% of the compiler’s algorithms (including all optimizations and all code generation algorithms) are proved correct in Rocq/Coq, but the remaining 10% (including elaboration, presimplifications, assembling and linking) are not verified. This can only improve in the future. Nonetheless, this incomplete formal verification already demonstrates major correctness improvements compared with ordinary compilers. Yang et al report:
The striking thing about our CompCert results is that the middle-end bugs we found in all other compilers are absent. As of early 2011, the under-development version of CompCert is the only compiler we have tested for which Csmith cannot find wrong-code errors. This is not for lack of trying: we have devoted about six CPU-years to the task. The apparent unbreakability of CompCert supports a strong argument that developing compiler optimizations within a proof framework, where safety checks are explicit and machine-checked, has tangible benefits for compiler users. [13]
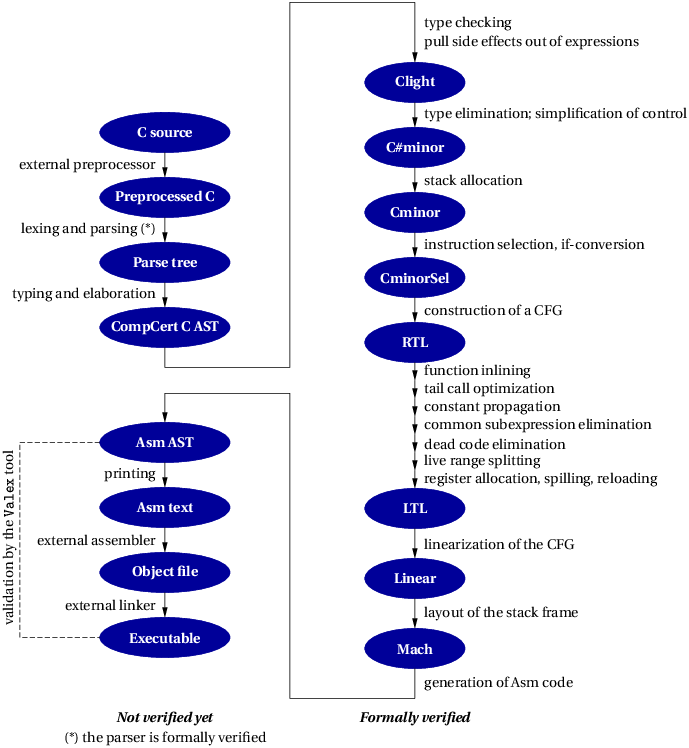
Figure 1.1: General structure of the CompCert C compiler
The general structure of the CompCert C compiler is depicted in Figure 1.1. The compilation of a C source file can be conceptually decomposed into the following phases:
As shown in Figure 1.1, only phase 3 (from CompCert C AST to Asm AST) and the parser in phase 2 are formalized and proved correct in Rocq/Coq. One reason is that some of the other phases lack a mathematical specification, making it impossible to state, let alone prove, a correctness theorem about them. This is typically the case for the preprocessing phase 1. Another reason is that the CompCert effort is still ongoing, and priority was given to the formal verification of the delicate compilation passes, especially of optimizations, which are all part of the verified phase 3. Future evolutions of CompCert will move more of phase 2 (unverified simplifications) into the verified phase 3. For phase 4 (assembly and linking), we have no formal guarantees yet, but the Valex tool, available from AbsInt, provides additional assurance via a posteriori validation of the executable produced by the external assembler and linker.
The main optimizations performed by CompCert are:
Loop optimizations are not performed yet.
CompCert C provides code generators for the following architectures:
Note that CompCert may utilize floating-point registers in certain situations unless the option -fno-fpu is specified (see section 3.2.4).
For each architecture, here are the supported Application Binary Interfaces (ABI) and operating systems:
| Architecture | ABI | OS |
| PowerPC | EABI and ELF/SVR4 | Linux (all 32-bit distributions) |
| ARM | EABI | Debian and Ubuntu GNU/Linux, armel or armeb architecture |
| EABI-HF | Debian and Ubuntu GNU/Linux, armhf or armebhf architecture | |
| AArch64 | AAPCS | Linux (all distributions) |
| macOS | macOS 11 and more recent | |
| x86 | ELF/SVR4 | Linux (all distributions), both 32 bits (i686) and 64 bits (x86_64) |
| macOS | macOS 10.9 and more recent (64 bits only) | |
| COFF | Microsoft Windows with the Cygwin environment | |
| RISC-V | ELF psABI | Linux |
Other operating systems that follow one of the ABI above could be supported with minimal effort.
Chapter 5 specifies the dialect of the C language that CompCert C accepts as input language. In summary, CompCert C supports all of ISO C 99 [5], with the following exceptions:
Consequently, CompCert supports all of the MISRA-C 2004 subset of C, plus many features excluded by MISRA-C, such as recursive functions and dynamic heap memory allocation.
A number of ISO C 2011 [6] features are also supported:
CompCert also supports some extensions to ISO C taken from the GNU and Diab compilers:

Figure 1.2: Performance of CompCert-generated AArch64 code on the Mibench benchmark suite, relative to GCC, on an ARM Cortex A72 processor. Shorter is better. The baseline, in yellow, is GCC without optimizations. CompCert is in red and blue.

Figure 1.3: Performance of CompCert-generated AArch64 code on a homemade benchmark suite, relative to GCC, on an ARM Cortex A72 processor. Shorter is better. The baseline, in red, is GCC without optimizations. CompCert is in blue.
On a variety of benchmarks and platforms, the code generated by CompCert runs generally twice as fast as the code generated by GCC without optimizations (gcc -O0), and approximately 10% slower than GCC at optimization level 1 (gcc -O1). Figures 1.2 and 1.3 show performance measurements on a 64-bit ARM processor for the Mibench benchmark suite and for miscellaneous other benchmarks. By lack of aggressive loop optimizations, performance is lower on codes involving lots of matrix computations.
CompCert attemps to generate object code that respects the Application Binary Interface of the target platform and that can, therefore, be linked with object code and libraries compiled by other C compilers. It succeeds to a large extent, as summarized in the following two tables.
Data representation and memory layout:
| Data type | ARM | PowerPC | x86-32 | x86-64 | RISC-V | AArch64 AAPCS | AArch64 macOS |
| Not containing long double FP numbers | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Containing long double FP numbers | ✔ | ✘ | ✘ | ✘ | ✘ | ✘ | ✔ |
Calling conventions (passing function arguments and returning function results):
| Type of argument or result | ARM EABI | ARM HF | PowerPC | x86-32 | x86-64 | RISC-V | AArch64 AAPCS | AArch64 macOS |
| Scalar types (see exceptions below) | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| — long double | ✔ | ✔ | ✘ | ✘ | ✘ | ✘ | ✘ | ✔ |
| — more than 8 FP arguments | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| — 8- and 16-bit integer arguments | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ |
| Struct and union types | ✘ | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | ✘ |
In some situations there are notable exceptions from ABI compatibility regarding the calling conventions and scalar types:
Here is a more detailed description of the ABI incompatibilities regarding the passing/returning of struct and union types mentioned above:
E.g. for a structure of size 2 bytes, CompCert and Diab will return the 2 data bytes in the high half of register r3. The low half of r3 and register r4 have an undefined values. In contrast to this GCC, returns the 2 data bytes in the low half of r3.
Structs and unions with a size larger than 8 bytes are returned by reference i.e., the result is written to a memory area allocated by the caller and provided to the function as additional first parameter.
The layout of fields in struct types follows the ELF ABI specifications. Regular fields are laid out consecutively at byte offsets that are multiple of their alignments. A bit field of type T is placed in a storage unit of size sizeof(T) and alignment alignof(T). This storage unit can overlap with the storage unit of the previous bit field or regular field if there is room.
In accordance with the ELF ABI specifications, the alignment of a struct or union type is the greatest of the alignments of its members, excluding unnamed bit fields. This introduces a small incompatibility with the AAPCS and AAPCS64 ABIs for ARM and AArch64, where unnamed bit fields are also taken into account for alignment determination.
On AArch64, CompCert does not maintain a chain of stack frames and instead treats the frame pointer register X29 as a general-purpose callee-saved register. On macOS, this behaviour is in conflict with the platform ABI.